AI推論はNAND SSDに何を求めているのか ― CMXという新しいメモリ階層
Computex で投資家から「TLC/QLC は書込耐久が悪いから、結局 SLC が AI で復権するのか」と何度も聞かれた、という話から始まる解説記事を読んだ。→ What AI Inference Actually Demands From a NAND SSD(Vik's Newsletter, 2026-06)
筆者の答えは「SLC か否か」という二択そのものが古い、というものだった。NAND を「1つの素材」ではなく「メモリ階層の中で複数のサブティアに分岐したもの」として見直すと、AI 推論時代に NAND ベンダーで何が起きるかが見えてくる、と展開していく。
ここでは公開部分(CMX という位置づけと、セル設計のトレードオフまで)を日本語で整理する。本論の途中までで、有料部分(CMX 向け SSD の I/O サイズ・FDP・ベンダー競争力)はリンク先で読んでほしい。
結論を先に出す。
- DRAM・HBM だけでは、エージェントが数時間〜数日かけて積み上げる数十TB級の KV-cache を抱えきれない。NAND SSD がメモリとストレージの間に新しい層を作りつつある(NVIDIA はこれを CMX = Context Memory Storage と呼んでいる)
- NAND の性格はセルあたり何ビット入れるかでほぼ決まる。状態数を増やすほど容量は伸びるが、書込速度と耐久は落ちる。逆に減らせばメモリ寄りになる
- だから「NAND = コモディティ」というモデルは古く、SSD は「メモリ寄りの層」「ストレージ寄りの層」に分岐しつつある。投資家が見るべきは「どのベンダーが各サブティアを押さえるか」
NAND がメモリ階層に新しい層を作った
エージェント型 AI が普及するにつれて、推論は「数分で終わるリクエスト」ではなくなった。タスクが数時間〜数日に伸び、その間ずっと過去のやり取り(コンテキスト)を抱えて参照し続ける必要が出てきた。
このコンテキストは KV-cache としてメモリに置く。1回のタスクで KV-cache が数十TBまで膨らむケースがあり、DRAM(HBM 含む)に置ききれない。HBM は容量当たり単価が最も高く、これだけで context を抱える設計は経済的に成立しない。
そこで NAND SSD が「メモリ寄りに調整された層」として推論パイプラインに割り込んできた。ストレージとしての NAND ではなく、decode 中に読みに行く文脈の置き場所としての NAND だ。なぜ「置き場所」ではなく「読みに行く先」と書いたかは次節で詳しく見る。DeepSeek v4 はこの前提で設計されていて、context を SSD にオフロードし、cache hit を最大化することでトークン単価を下げている。
NVIDIA はこの層を CMX(Context Memory Storage) と呼んでいる。HBM と通常の Storage SSD の間にもう1段、メモリ寄りに調整された NAND の層がある、という地図である。

ここで CXL(CPU-Attached のプール DRAM)も同じ位置を狙うのではないか、という反論はある。CXL は別の有力候補で、メモリ階層上では NAND CMX とまた別のティアを占める。本論ではいったん脇に置く。
なぜ「ストレージ」ではなく「メモリ」として NAND が要るのか
ここが多くの人が腑に落ちないところだと思うので、噛み砕いて書く。LLM 推論には性質の違う2フェーズがあることを先に押さえると、KV-cache の置き場所がなぜ経済性を決めるかが見える。
- prefill: ユーザーが投げ込んだプロンプト全体を一気に行列計算し、各トークンの K/V(Key / Value ベクトル)を求める。GPU の計算ユニットがフル回転する計算支配フェーズ
- decode: 1トークンずつ生成する。1トークン出すたびに、過去の全トークンの K/V を毎回読みに行く。計算量自体は小さいが、メモリから KV-cache を流し込む帯域がボトルネックになるメモリ支配フェーズ
つまり KV-cache は「履歴を残すための保存場所」ではなく、次の1トークンを出すたびに毎回スキャンされる作業領域である。ユーザーが応答1文字を読むあいだに、その人の過去全文の K/V が一通り読み出されている、というイメージが正しい。
エージェントが普及して、ここに3つのことが同時に起きた。
- 1ユーザーあたりのコンテキストが10万〜100万トークンに伸びる(コードベース全体、ドキュメント、過去の会話履歴を抱えたまま作業する)
- モデルが大きくなるほど1トークンあたりの K/V サイズも大きくなり、Llama 3 70B 級では1トークン数百KB、100万トークンで数百GB / 人
- 1サーバーで何百ユーザーを並行処理する設計なので、ホットな KV-cache の合計が数十TB / サーバーに膨らむ
ここで HBM・DRAM だけで凌ごうとすると経済性が壊れる。
- HBM: GPU 直結で最速だが容量が数百GB級。1人分でも溢れる
- CPU 側 DRAM: TB クラスまで積めるが、数十TBを単一サーバーで持つのは単価が高すぎる
- 従来の Storage SSD: 容量は出るが、レイテンシが μs〜ms オーダーで、1トークン生成のレイテンシ予算(数ms)の中で間に合わない場面がある
だから「DRAM ほど高速ではないが、Storage SSD よりは速く、容量当たり単価では NAND」という新しい層が必要になる。これが CMX。decode 中に GPU が KV-cache を取りに来た時、μs オーダーで応答できる NAND、というのが要件になる。
「永続化のために NAND を使う」のは Storage SSD の発想で、「毎秒何千回も読みに行かれることを前提に、メモリのように振る舞う NAND」が CMX の発想、と切り分けると伝わりやすい。両者は同じ NAND チップを使っていても、コントローラ・I/O サイズ・ファームウェアの最適化が別物になる。
ここまで掴めれば、後の「セルあたり何ビット詰めるか」のトレードオフが、なぜ単なる容量の話ではなくメモリとしての性格を決める設計選択なのかが繋がる。
NAND の性格は「セルあたり何ビット入れるか」で決まる
「メモリ寄り」「ストレージ寄り」を作り分けられる、というのは抽象的に聞こえるが、根っこにあるのは1つの単純な設計選択だ。セル1個に何ビット詰めるか。
NAND は電子の蓄え量で 0/1 を表す素子で、N レベルセルは 2^N 個の電圧状態を1つのセルに詰める。SLC(N=1)は 0/1 の2状態だけ、QLC(N=4)は 0000〜1111 の16状態を区別する。同じ面積に多くの状態を詰めれば容量は増えるが、その代償が3つある。
- 書込速度: 書込みは ISPP(Incremental Step Pulse Programming)という、電圧を少しずつ上げながら目標状態に追い込む反復処理で行う。区別したい状態数が多いほど、塗り分けが細かくなり、反復回数が増えて遅くなる
- 耐久: 書込みを繰り返すと酸化膜が劣化し、状態を区別する電圧の境目がずれる。SLC は境目が1つだけだから多少ずれても判定できるが、QLC は15本の境目を全部維持しないとビットエラーが増える
- 温度・経年でのドリフト耐性: 同じく、状態数が多いほど境目がぶれた時の許容範囲が狭い
この3つを表に並べると、SLC〜QLC の性格差がはっきりする。

ハイブリッド設計で「メモリ寄り」「ストレージ寄り」を作り分ける
実際の SSD は SLC〜QLC のどれか1つで作るとは限らない。TLC 本体に SLC キャッシュを載せる、という構成が主流で、書込みが集中する小領域だけ高速・高耐久にし、本体は容量を稼ぐ。読み出しが支配的なワークロード向けには SLC キャッシュをほぼ無効化して TLC の容量を全部出す、といった調整もできる。
CMX 用 SSD はこのハイブリッド設計の方向で「メモリ寄り」に振った製品になる。Storage SSD として最大容量を狙う製品とは別系統で、
- 読み出しスループットを decode の token 速度に間に合わせる
- 書込みは KV-cache の追記が中心で、ランダム小書込みを高頻度でこなす
- I/O サイズを細かく刻めるよう、内部の indirection unit(IU)を小さくする
- **書込み増幅(WAF)**を抑えるため、FDP(Flexible Data Placement)でホスト側からデータの寿命を教える
このあたりは原文の有料部分で詳しく展開されている。共通して言えるのは、NAND は「容量と速度のどこに寄せるか」を製品レベルで選び分ける時代に入っているということだ。
ベンダーの製品ロードマップが分岐を裏付けている ― KIOXIA の例
ここまでの話は理屈の整理だが、NAND 最大手の1つである KIOXIA は、2026年の決算説明会で「AI 推論システム向け SSD/NAND への要求」というスライドを出していて、この分岐をそのまま製品ライン化している。
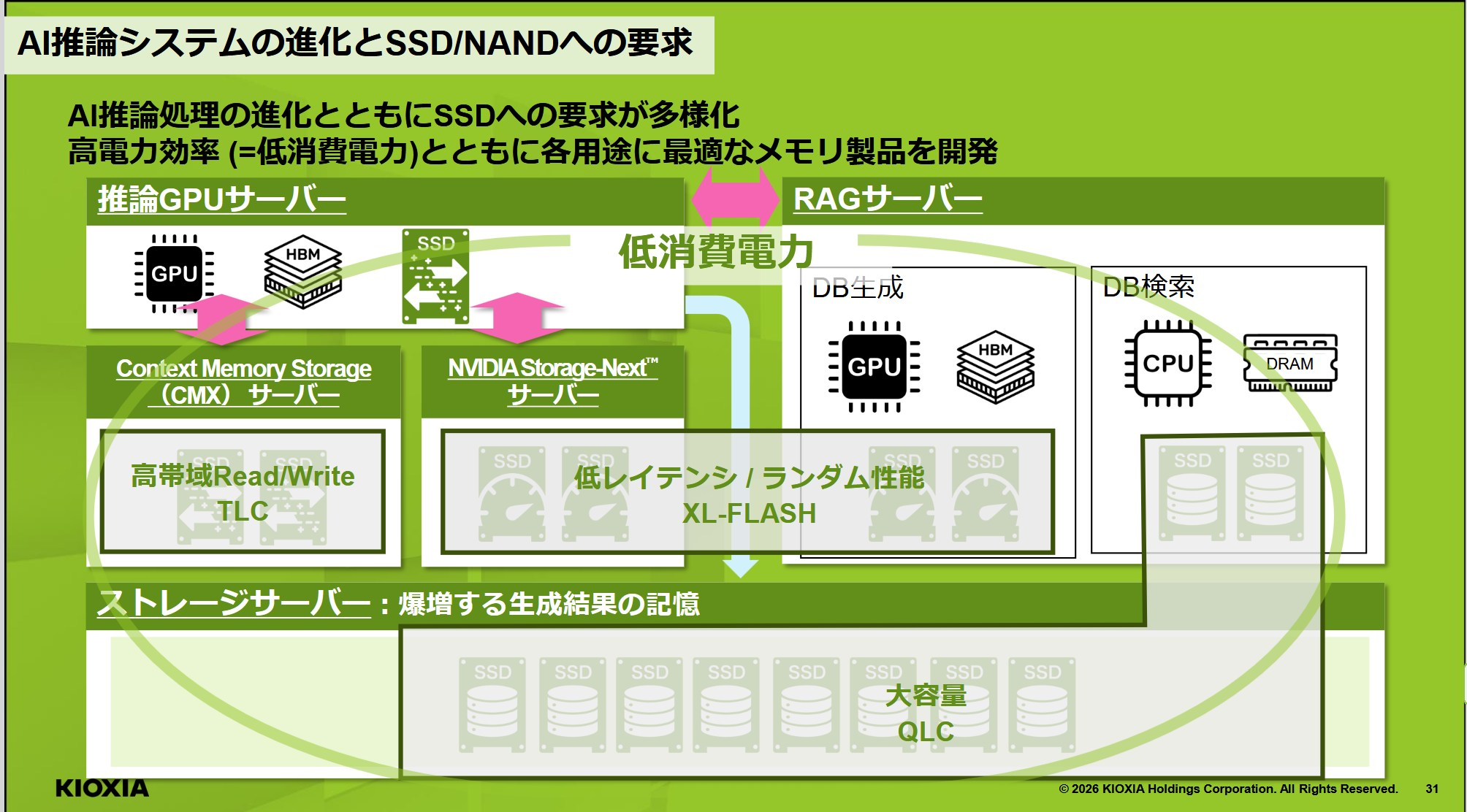
このスライドを読み解くと、用途と NAND 種別の対応がはっきり書かれている。
- Context Memory Storage (CMX) サーバー = TLC: 高帯域 Read/Write が要件。KV-cache を decode 中に流し込む層
- NVIDIA Storage-Next サーバー = XL-FLASH: 低レイテンシ / ランダム性能が要件。RAG や Vector DB のような「大量の小さな読み出し」が支配的なワークロード向け
- ストレージサーバー = QLC: 大容量。生成結果や生データの永続化用
- RAG サーバー: GPU+HBM(DB生成)/ CPU+DRAM(DB検索)の組み合わせで、NAND は脇役
XL-FLASH は KIOXIA の高速 NAND ブランドで、SLC ベースでレイテンシを数 μs まで詰めた製品系列だ。Intel が 3D XPoint(Optane)から撤退した後、「DRAM ほど速くはないが通常 NAND よりはるかに速い」ストレージクラスメモリの位置を狙っている。同じ NAND チップから派生していても、CMX 向けの TLC とは別物の最適化が施されている。
NVIDIA Storage-Next は NVIDIA が定義した次世代の高速ストレージインターフェース仕様で、GPUDirect Storage 系の発展形にあたる。GPU から直接 SSD を叩く経路でレイテンシ・ランダム性能を稼ぐ設計で、ここに XL-FLASH を載せるのが KIOXIA の解、ということになる。
つまり1社の中ですら、AI 推論向け SSD は少なくとも3つの製品ラインに分岐している。「NAND = 1つのコモディティ」というモデルではこの分岐は説明できない。「用途別の性能サブティア」として見ると、ベンダーが何を作っているかが素直に読める。
他社(Samsung、SK Hynix・Solidigm、Micron、WDC など)も同様の用途別ロードマップを順次出してくるはずで、CMX 用 TLC・SCM 用 SLC(XL-FLASH 相当)・大容量 QLC のそれぞれで誰が先頭を取るかが、これからの NAND 投資の見どころになる。
投資家視点で何が起きるか
ここから先は原文の問題提起で、答えは有料部分にある。要点だけ書く。
- NAND は「1つの素材」ではなく「メモリ寄りのサブティア / ストレージ寄りのサブティア」に分岐しつつある
- CMX 向けの SSD は、容量だけ追えばよい従来の Storage SSD とは別の最適化が要求される(I/O サイズ・WAF・FDP・非対称な read/write 帯域)
- どのベンダーがどのサブティアを押さえているかで、AI 推論時代の NAND 市場の勝敗が決まる
投資家として手元のチェックリストに追加するなら、Micron・SK Hynix・Samsung・Kioxia・WDC・Solidigm のどこが「CMX 向け SSD のスペックシートを最初に出すか」「FDP 対応をどう進めるか」あたりを見ておくと、ニュースの読み方が変わる。
ここから先(CMX 向け SSD の具体仕様と各社の競争力)は元記事を読むのが早い。
→ What AI Inference Actually Demands From a NAND SSD(Vik's Newsletter)