NVIDIA 2026年度第3四半期決算説明会 全文書き起こし
開催日: 2025年11月19日 登壇者: ジェンスン・フアン(CEO)、コレット・クレス(CFO)
概要
NVIDIAの2026年度第3四半期決算説明会では、売上高570億ドル(前年同期比62%増)を達成し、Blackwell・Rubinプラットフォームで2026年末までに5,000億ドルの売上見通しを発表。AI市場の3つの主要な移行(アクセラレーテッド・コンピューティング、生成AI、エージェントAI)が成長を牽引している。

要約: データセンター売上高510億ドル(前年比66%増)を達成。GB300の立ち上げでコンピュート部 門56%成長、ネットワーキング部門は2倍以上の成長。
オープニング
オペレーター (Sarah): こんにちは。本日はオペレーターを務めますサラと申します。この度は、NVIDIAの第3四半期決算説明会にご参加いただき、誠にありがとうございます。 バックグラウンドノイズを防ぐため、すべての回線はミュートされています。スピーカーの発言の後、質疑応答の時間を設けます。その際、質問がある場合は「」と「1」を押してください。質問を取り下げる場合は「」と「1」を再度押してください。 それでは、Toshia Hariさん、会議を始めてください。
Toshia Hari (IR部門): ありがとうございます。皆様、こんにちは。NVIDIAの2026年度第3四半期決算説明会へようこそ。 本日は、NVIDIAより社長兼CEOのジェンスン・フアン(Jensen Huang)、およびエグゼクティブ・バイスプレジデント兼CFOのコレット・クレス(Colette Kress)が出席しています。
この電話会議は、NVIDIAの投資家向け広報ウェブサイトでライブ配信されていることをお知らせします。ウェブキャストは、2026年度第4四半期の決算発表会議まで再生可能です。本日の電話会議の内容はNVIDIAの財産であり、事前の書面による同意なしに複製や転写を行うことはできません。
本日の電話会議では、現在の予想に基づく将来の見通しに関する記述を行う場合があります。これらは重大なリスクや不確実性の影響を受ける可能性があり、実際の結果は大きく異なる可能性があります。将来の業績や事業に影響を与えうる要因については、本日の決算短信、最新のフォーム10-Kおよび10-Q、および証券取引委員会(SEC)に提出するフォーム8-Kをご参照ください。
すべての記述は、現在入手可能な情報に基づき、本日2025年11月19日時点で行われるものです。法律で義務付けられている場合を除き、当社はこれらの記述を更新する義務を負いません。 また、本日はGAAP基準以外の財務指標についても議論します。これらの調整表は、当社のウェブサイトに掲載されているCFOコメントにてご確認いただけます。 それでは、コレットにマイクを渡します。
CFO業績報告(コレット・クレス)
第3四半期ハイライト
要約: 売上高570億ドル(前年比62%増、前四半期比22%増)を達成。Blackwell・Rubinで5,000億ドルの売上見通しを発表し、2030年までのAIインフラ市場3〜4兆ドルでリーダーシップを維持する戦略を提示。
コレット・クレス (CFO): ありがとう、Toshia。 当社は再び素晴らしい四半期を達成しました。売上高は570億ドルで、前年同期比62%増となり、前四半期比でも100億ドル増(22%増)という記録的な成長を遂げました。
お客様は引き続き3つのプラットフォームシフトに注力しており、これがアクセラレーテッド・コンピューティング、強力なAIモデル、そしてエージェントAI(Agentic AI)の指数関数的な成長を後押ししています。しかし、あらゆる業界の業務に影響を与えるこれらの移行は、まだ初期段階にあります。
現在、今年初めから2026暦年末までの期間において、Blackwell(ブラックウェル)およびRubin(ルービン)による売上について、5,000億ドル(半兆ドル)規模の視界を持っています。毎年の製品投入サイクルを実行し、フルスタック設計によってパフォーマンスのリーダーシップを拡大することで、10年代の終わりまでに年間3兆〜4兆ドルと見積もられるAIインフラ構築において、NVIDIAが最適な選択肢であり続けると確信しています。
AIインフラへの需要は引き続き当社の予想を上回っています。クラウドは完売状態であり、Blackwell、Hopper、Ampereを含む新旧世代のGPUインストールベースは完全に稼働しています。
データセンター事業の成長
要約: データセンター売上高510億ドル(前年比66%増)を達成。GB300の立ち上げでコンピュート部門56%成長、ネットワーキング部門は2倍以上の成長。ハイパースケーラーの設備投資は6,000億ドルに達し、年初から2,000億ドル増加。
第3四半期のデータセンター売上高は記録的な510億ドルとなり、前年同期比66%増となりました。これは当社の規模を考えると驚異的な成果です。 コンピュート(計算用GPU)は、主にGB300の立ち上げにより前年同期比56%成長しました。一方、ネットワーキングは、NVLinkスケールアップの開始と、Spectrum-XイーサネットおよびQuantum-Xインフィニバンドの堅調な2桁成長により、2倍以上に増加しました。
世界のハイパースケーラー(1兆ドル規模の産業)は、検索、レコメンデーション、コンテンツ理解を、従来の機械学習から生成AIへと転換しています。NVIDIA CUDAは両方の分野で優れており、この移行のための理想的なプラットフォームです。これにより、数千億ドル規模のインフラ投資が推進されています。
Metaでは、AIレコメンデーションシステムがより高品質で関連性の高いコンテンツを提供しており、FacebookやThreadsなどのアプリでの滞在時間の増加につながっています。 アナリストの予想では、トップCSP(クラウドサービスプロバイダー)およびハイパースケーラーの2026年の設備投資額(CapEx)の合計は増加し続けており、現在約6,000億ドルに達しています。これは年初と比較して2,000億ドル以上の増加です。
現在のハイパースケール・ワークロードにおけるアクセラレーテッド・コンピューティングと生成AIへの移行は、当社の長期的な機会の約半分に寄与すると見ています。
基盤モデルビルダーとエージェントAI
要約: OpenAI(週間8億ユーザー)、Anthropic(年間経常収益70億ドル)などの基盤モデル構築者が急成長。3つのスケーリング則(事前学習、事後学習、推論)が有効に機能し、エージェントAIが様々な業界で明確なROIを提供。
もう一つの成長の柱は、Anthropic、Mistral、OpenAI、Reflection、Safe Superintelligence、Thinking Machines Lab、xAIなどの基盤モデル構築者によるコンピュート支出の継続的な増加です。これらはすべて、知能を拡大するためにコンピュートを積極的に拡大しています。
3つのスケーリング則(事前学習、事後学習、推論)は引き続き有効です。実際、これら3つのスケーリング則とコンピュートへのアクセスがより良い知能を生み出し、それがさらなる採用と利益の増加につながるというポジティブな好循環が生まれています。
OpenAIは最近、週間ユーザー数が8億人に増加し、エンタープライズ顧客が100万人に達したこと、そして粗利益率が健全であることを明らかにしました。 一方、Anthropicは最近、年換算の経常収益が先月時点で70億ドルに達したと報告しました。これは年初の10億ドルからの急増です。
また、様々な業界やタスクにおいて「エージェントAI」の普及も目撃しています。 Cursor、Anthropic、Open Evidence、Epic、Abridgeなどの企業は、ユーザー数の急増を経験しています。これらは既存の労働力を強化し、コーダーや医療専門家に疑いの余地のないROI(投資対効果)を提供しています。
エンタープライズAI導入事例
要約: ServiceNow、CrowdStrike、SAP、Palantirなどの主要エンタープライズソフトウェアがNVIDIA AIスタックを統合。RBC、Unilever、Salesforceなどで30〜50%の生産性向上を実現し、明確なROIを提供。
ServiceNow、CrowdStrike、SAPといった世界で最も重要なエンタープライズ・ソフトウェア・プラットフォームは、NVIDIAのアクセラレーテッド・コンピューティングとAIスタックを統合しています。 当社の新しいパートナーであるPalantirは、非常に人気のあるOntologyプラットフォームを、NVIDIA CUDA-XライブラリとAIモデルで初めて強化しています。以前は、他の多くのエンタープライズ・ソフトウェアと同様、OntologyはCPU上でのみ動作していました。 Lowe's(ロウズ)はこのプラットフォームを活用してサプライチェーンの俊敏性を構築し、コスト削減と顧客満足度の向上を実現しています。
企業は広くAIを活用して生産性を高め、効率を上げ、コストを削減しています。 RBCはエージェントAIを活用してアナリストの生産性を大幅に向上させ、レポート作成時間を数時間から数分に短縮しました。 AIとデジタルツインは、Unileverのコンテンツ作成を2倍に加速し、コストを50%削減するのに役立っています。 Salesforceのエンジニアリングチームは、Cursorの導入後、新しいコード開発において少なくとも30%の生産性向上を確認しています。
主要AIインフラプロジェクト
要約: 第3四半期に合計500万基のGPU相当のプロジェクトを発表。xAI「Colossus 2」は世界初のギガワット級データセンター、AWS-Humaneパートナーシップで最大15万基のアクセラレータ配備を発表。
この四半期、当社は合計500万基のGPUに相当するAIファクトリーおよびインフラプロジェクトを発表しました。この需要は、CSP、ソブリン(国家主導)、モデルビルダー、エンタープライズ、スーパーコンピューティングセンターなど、あらゆる市場に及び、複数の画期的な構築案件が含まれています。
xAIの「Colossus 2」は世界初のギガワット規模のデータセンターです。 Eli Lilly(イーライリリー)の創薬AIファクトリーは、製薬業界で最も強力なデータセンターです。
そして本日、AWSとHumane(ヒューメイン)はパートナーシップを拡大し、当社のGB300を含む最大15万基のAIアクセラレータの配備を発表しました。xAIとHumaneも、500メガワットの主力施設を中心とした世界クラスのGPUデータセンターネットワークを共同開発するパートナーシップを発表しました。
Blackwell・Hopperプラットフォーム
要約: GB300がBlackwell売上の3分の2を占め、主要CSPへの量産出荷が成長を牽引。Hopperは発表から13四半期目で20億ドルの売上。中国市場は地政学的問題で伸び悩むが、グローバル展開を継続。
Blackwellは第3四半期にさらなる勢いを得ました。**GB300がGB200を上回り、Blackwellの総売上の約3分の2を占めるようになりました。**GB300への移行はシームレスに行われ、主要なCSP、ハイパースケーラー、GPUクラウドへの量産出荷がすでに彼らの成長を牽引しています。
Hopperプラットフォームは、発表から13四半期目を迎え、第3四半期に約20億ドルの売上を記録しました。H20売上高は約5,000万ドルでした。 地政学的な問題と中国市場での競争激化により、大規模な発注はこの四半期には実現しませんでした。 中国へより競争力のあるデータセンター製品を出荷できない現状には失望していますが、米国および中国政府との継続的な関与にコミットしており、米国が世界中で競争する能力を引き続き主張していきます。
AIコンピューティングにおける持続可能なリーダーシップを確立するためには、米国はすべての開発者の支持を獲得し、中国を含むあらゆる商業ビジネスにとって最適なプラットフォームでなければなりません。
GPU世代ロードマップ

Rubinプラットフォーム
要約: 2026年後半リリース予定のRubin(Vera Rubin)は7チップ構成でBlackwellから再び「Xファクター」の性能向上を実現。第3世代ラックスケールシステムでGrace Blackwellとの互換性を維持。
Rubin(ルービン)プラットフォームは、2026年後半の立ち上げに向けて順調に進んでいます。7つのチップを搭載したVera Rubinプラットフォームは、Blackwellと比較して再び「Xファクター(未知数レベルの)」性能向上をもたらします。サプライチェーンパートナーからシリコンを受け取り、世界中のNVIDIAチームが立ち上げを見事に実行していることを報告できて嬉しく思います。
Rubinは当社の第3世代ラックスケールシステムであり、製造性を大幅に再定義しつつ、Grace Blackwellとの互換性を維持しています。当社のサプライチェーン、データセンターエコシステム、クラウドパートナーは、NVIDIAのラックアーキテクチャの構築から設置までのプロセスを習得しました。当社のエコシステムは、迅速なRubinの立ち上げに向けて準備が整うでしょう。
CUDAエコシステムの優位性
要約: 20年以上のCUDA投資により、6年前のA100でも最新ソフトウェアでフル稼働可能。毎年のXファクター性能向上とTCO優位性で、他社アクセラレータを大きく凌駕。
当社の毎年のXファクター性能向上は、顧客のコストあたりの性能を向上させ、計算コストを引き下げます。NVIDIA CUDA GPUの長い耐用年数は、アクセラレータと比較してTCO(総所有コスト)で大きな優位性をもたらします。CUDAの互換性と当社の巨大なインストールベースは、NVIDIAシステムの寿命を当初の見積もりをはるかに超えて延長します。
20年以上にわたり、当社はCUDAエコシステムを最適化し、ソフトウェアのリリースごとに既存のワークロードを改善し、新しいワークロードを加速させ、スループットを向上させてきました。CUDAとNVIDIAの実証済みで汎用性の高いアーキテクチャを持たない多くのアクセラレータは、モデル技術の進化に伴い数年で陳腐化しました。 CUDAのおかげで、6年前に出荷したA100 GPUは、大幅に改善されたソフトウェアスタックにより、今日でもフル稼働しています。
当社は過去25年間で、ゲーミングGPU企業からAIデータセンターインフラ企業へと進化しました。CPU、GPU、ネットワーキング、ソフトウェア全体で革新し、最終的にトークンあたりのコストを引き下げる当社の能力は、業界で比類のないものです。
ネットワーキング事業
要約: ネットワーキング売上82億ドル(前年比162%増)を達成し、世界最大のAI向けネットワーキング企業に。NVLink、InfiniBand、Spectrum-Xイーサネットすべてが成長し、イーサネットGPU装着率はInfiniBandと同等に。
AI向けに専用設計され、現在世界最大となった当社のネットワーキング事業は、82億ドルの売上を生み出し、前年同期比162%増となりました。NVLink、InfiniBand、Spectrum-Xイーサネットのすべてが成長に寄与しました。 AI展開の大部分に当社のスイッチが含まれるようになり、データセンターネットワーキングで勝利を収めています。イーサネットGPUの装着率はInfiniBandとほぼ同等になっています。
Meta、Microsoft、Oracle、xAIは、Spectrum-Xイーサネットスイッチを使用してギガワット級のAIファクトリーを構築しており、それぞれが選択したオペレーティングシステムを実行します。これは当社プラットフォームの柔軟性とオープン性を強調するものです。
最近、ギガスケールのAIファクトリーを可能にするスケールアクロス技術であるSpectrum-X GSを発表しました。NVIDIAは、AIのスケールアップ、スケールアウト、スケールアクロスのプラットフォームを持つ唯一の企業であり、AIインフラプロバイダーとしての独自の地位を強化しています。
NVLink Fusionとエコシステム連携
要約: 富士通、Intel、Armとの戦略的提携によりNVLinkエコシステムを拡大。第5世代NVLinkは市場唯一の実証済みスケールアップ技術として業界標準化を推進。
NVLink Fusionに対する顧客の関心は高まり続けています。10月には富士通との戦略的提携を発表し、NVLink Fusionを通じて富士通のCPUとNVIDIAのGPUを統合し、大規模なエコシステムを接続します。 また、Intelとの提携も発表し、NVLinkを使用してNVIDIAとIntelのエコシステムを接続する複数世代のカスタムデータセンターおよびPC製品を開発します。
今週のSupercomputing 25で、ArmはNVLink IPを統合し、顧客がNVIDIAと接続するCPU SoCを構築できるようにすると発表しました。現在第5世代となるNVLinkは、市場で唯一の実証済みスケールアップ技術です。
ベンチマーク性能
要約: MLPerfでBlackwell UltraがHopperの5倍高速、唯一のFP4対応プラットフォーム。InferenceMaxでDeepSeek R1においてH200比でワットあたり10倍の性能、トークンあたり10分の1のコストを達成。
最新のMLPerfトレーニング結果において、Blackwell UltraはHopperと比較して5倍高速なトレーニング時間を提供しました。NVIDIAはすべてのベンチマークを席巻しました。特筆すべきは、NVIDIAがMLPerfの厳格な精度基準を満たしながらFP4を活用できる唯一のトレーニングプラットフォームであることです。
SemiAnalysisのInferenceMaxベンチマークでは、Blackwellはすべてのモデルとユースケースにおいて最高のパフォーマンスと最低のTCOを達成しました。特に重要なのは、世界で最も人気のある推論モデルのアーキテクチャであるMoE(Mixture of Experts)におけるBlackwellのNVLinkパフォーマンスです。 DeepSeek R1において、BlackwellはH200と比較してワットあたり10倍の性能と、トークンあたり10倍低いコストを実現しました。これは当社の極端な協調設計アプローチによってもたらされた巨大な世代的飛躍です。
NVIDIA Dynamo(オープンソースの低遅延モジュラー推論フレームワーク)は、すべての主要なクラウドサービスプロバイダーに採用されました。Dynamoのイネーブルメントと分離型推論を活用することで、AWS、Google Cloud、Microsoft Azure、OCIは、MoEモデルなどの複雑なAIモデルのパフォーマンスを向上させ、エンタープライズクラウド顧客向けのAI推論パフォーマンスをブーストしました。
戦略的パートナーシップ
要約: OpenAIと10ギガワット規模のデータセンター構築支援で提携、出資機会も検討。Anthropicと初の技術パートナーシップで最大1ギガワットのコンピュート提供。戦略的投資でCUDA AIエコシステムを拡大。
当社はOpenAIとの戦略的パートナーシップに取り組んでおり、少なくとも10ギガワットのAIデータセンターの構築と展開を支援することに焦点を当てています。さらに、同社への出資の機会もあります。 当社はMicrosoft Azure、OCI、CoreWeaveなどのクラウドパートナーを通じてOpenAIにサービスを提供しており、当面の間これを継続します。彼らが規模を拡大し続ける中で、同社が自社構築のインフラを追加することを支援できることを嬉しく思い、最終合意に向けて作業を進めており、OpenAIの成長を支援することを楽しみにしています。
昨日、Anthropicとの発表を祝いました。初めてAnthropicがNVIDIAを採用し、彼らの急成長を支援するための深い技術パートナーシップを確立します。CUDA向けにAnthropicのモデルを最適化し、最高のパフォーマンス、効率、TCOを提供するために協力します。また、Anthropicのワークロード向けに将来のNVIDIAアーキテクチャも最適化します。 Anthropicのコンピュートへのコミットメントには、当初、Grace BlackwellおよびVera Rubinシステムによる最大1ギガワットの計算能力が含まれています。
Anthropic、Mistral、OpenAI、Reflection、Thinking Machinesなどへの当社の戦略的投資は、NVIDIA CUDA AIエコシステムを成長させ、あらゆるモデルがあらゆる場所のNVIDIA上で最適に動作するようにするためのパートナーシップを表しています。 当社はキャッシュフロー管理への規律あるアプローチを維持しながら、戦略的に投資を継続します。
フィジカルAIとOmniverse
要約: フィジカルAIは数十億ドル規模のビジネスで、数兆ドル規模の機会。PTC・Siemens、Toyota・TSMC等がOmniverseデジタルツイン採用。Agility、Amazon Robotics、FigureなどがCosmos・Omniverse・Jetsonで次世代ロボット開発。
フィジカルAI(Physical AI)はすでに数十億ドル規模のビジネスであり、数兆ドル規模の機会に対応するNVIDIAの次の成長の柱です。米国の主要メーカーやロボットイノベーターは、NVIDIAの3コンピュータ・アーキテクチャを活用して、NVIDIA上でトレーニングを行い、Omniverseコンピュータ上でテストし、Jetsonロボットコンピュータ上で現実世界のAIを展開しています。
PTCとSiemensは、Omniverseを活用したデジタルツイン・ワークフローを広範な顧客ベースにもたらす新サービスを導入しました。 Belden、Caterpillar、Foxconn、Lucid Motors、Toyota、TSMC、Wistronなどの企業は、AI主導の製造と自動化を加速するためにOmniverseデジタルツインファクトリーを構築しています。
Agility Robotics、Amazon Robotics、Figure、Skild AIなどは、開発用のNVIDIA Cosmosワールド・ファウンデーションモデル、シミュレーションと検証用のOmniverse、次世代のインテリジェントロボットを動かすためのJetsonなどの製品を活用して、当社のプラットフォーム上で構築を行っています。
サプライチェーン強化
要約: TSMCとの提携で米国本土初のBlackwellウェハーを生産。Foxconn、Wistron、Amkor、Spilと協力し、今後4年間で米国でのプレゼンスを拡大。
当社は、グローバルサプライチェーンにおける回復力と冗長性の構築に引き続き注力しています。先月、TSMCとの提携により、米国本土で生産された最初のBlackwellウェハーを祝いました。今後4年間で米国でのプレゼンスを拡大するために、Foxconn、Wistron、Amkor、Spilなどと引き続き協力していきます。
その他の事業セグメント
ゲーミング
要約: 売上高43億ドル(前年比30%増)。Blackwellの勢い継続、Steam同時接続4,200万人の記録更新、GeForce 25周年を迎える。
ゲーミング売上高は43億ドルで、前年同期比30%増となりました。これはBlackwellの勢いが継続し、強い需要に牽引されたものです。エンドマーケットの実売は堅調で、ホリデーシーズンに向けてチャネル在庫は正常なレベルにあります。 Steamは最近、同時接続ユーザー数の記録を更新し、4,200万人のゲーマーを記録しました。また、韓国で開催されたGeForceゲーマーフェスティバルには数千人のファンが詰めかけ、GeForceの25周年を祝いました。
プロフェッショナル・ビジュアライゼーション
要約: 売上高7億6,000万ドル(前年比56%増)で記録更新。世界最小のAIスーパーコンピューターDGX Sparkが成長を牽引。
NVIDIAプロフェッショナル・ビジュアライゼーションは、グラフィックスであれAIであれ、エンジニアや開発者のためのコンピュータへと進化しました。 プロフェッショナル・ビジュアライゼーションの売上高は7億6,000万ドルで、前年同期比56%増となり、こちらも記録を更新しました。成長は、Grace Blackwellの小規模構成で構築された世界最小のAIスーパーコンピューターであるDGX Sparkによって牽引されました。
自動車
要約: 売上高5億9,200万ドル(前年比32%増)。自動運転ソリューションが牽引し、UberとHyperion L4ロボタクシーで世界最大のレベル4自動運転フリート構築。
自動車向け売上高は5億9,200万ドルで、前年同期比32%増となりました。これは主に自動運転ソリューションによって牽引されています。 当社はUberと提携し、新しいNVIDIA Hyperion L4ロボタクシー・リファレンス・アーキテクチャに基づいて構築された、世界最大のレベル4対応自動運転フリートを拡大しています。
財務指標と第4四半期見通し
要約: Q3粗利益率73.6%(非GAAP)で予想上回る。Q4売上見通し650億ドル(前四半期比14%成長)、粗利益率75.0%(非GAAP)を見込む。在庫32%増・供給コミットメント63%増で大幅成長に備える。
損益計算書の残りの部分に移ります。 GAAP粗利益率は73.4%、非GAAP粗利益率は73.6%となり、当社の見通しを上回りました。粗利益率は、データセンターのミックス、サイクルタイムの改善、コスト構造により、前四半期比で増加しました。
GAAP営業費用は前四半期比8%増、非GAAPベースでは11%増でした。この増加は、インフラストラクチャ・コンピュート、およびエンジニアリング開発コストにおける報酬と福利厚生の増加によるものです。
第3四半期の非GAAP実効税率は17%強で、米国の収益が好調だったため、ガイダンスの16.5%を上回りました。
バランスシートでは、在庫は前四半期比32%増加し、供給コミットメントは前四半期比63%増加しました。当社は今後の大幅な成長に備えており、機会セットに対して実行する能力に自信を持っています。
それでは、第4四半期の見通しについて説明します。 総売上高は650億ドル(プラスマイナス2%)を見込んでいます。中間値において、当社の見通しは前四半期比14%の成長を意味しており、Blackwellアーキテクチャの継続的な勢いが牽引します。 前四半期と同様、中国からのデータセンター・コンピュート売上は想定していません。
GAAPおよび非GAAPの粗利益率は、それぞれ74.8%および75.0%(プラスマイナス50ベーシスポイント)を見込んでいます。 2027年度に向けては、投入コストは上昇傾向にありますが、粗利益率を70%台半ばに維持するよう努めています。
GAAPおよび非GAAPの営業費用は、それぞれ約67億ドルおよび50億ドルを見込んでいます。 GAAPおよび非GAAPのその他収益および費用は、非市場性および公開株式証券からの損益を除き、約5億ドルの収益を見込んでいます。 GAAPおよび非GAAPの税率は、個別項目を除き、17%(プラスマイナス1%)を見込んでいます。
それでは、ジェンスンに代わります。
CEOビジョン説明(ジェンスン・フアン)
AIバブル論への反論と3つのプラットフォームシフト
要約: 「AIバブル」論に対し、NVIDIAは3つの巨大なプラットフォームシフトを同時に経験していると説明。①アクセラレーテッド・コンピューティング(基礎的)、②生成AI(変革的)、③エージェントAI(革命的)が、それぞれ数千億〜数兆ドル規模のインフラ投資を牽引。単一アーキテクチャでこれら全てをカバーする優位性を強調。
ジェンスン・フアン (CEO): ありがとう、コレット。 「AIバブル」について多くの議論がなされています。しかし、私たちの視点からは全く異なる景色が見えています。 改めて申し上げますが、NVIDIAは他のどのアクセラレータとも異なります。 私たちは、事前学習、事後学習から推論に至るまで、AIのあらゆるフェーズで優れています。そして、20年にわたるCUDA-Xアクセラレーションライブラリへの投資により、科学技術シミュレーション、コンピュータグラフィックス、構造化データ処理、従来の機械学習においても卓越しています。
世界は今、ムーアの法則の夜明け以来初めて、3つの巨大なプラットフォームシフトを同時に経験しています。NVIDIAは、これら3つの変革のそれぞれに独自に対応しています。
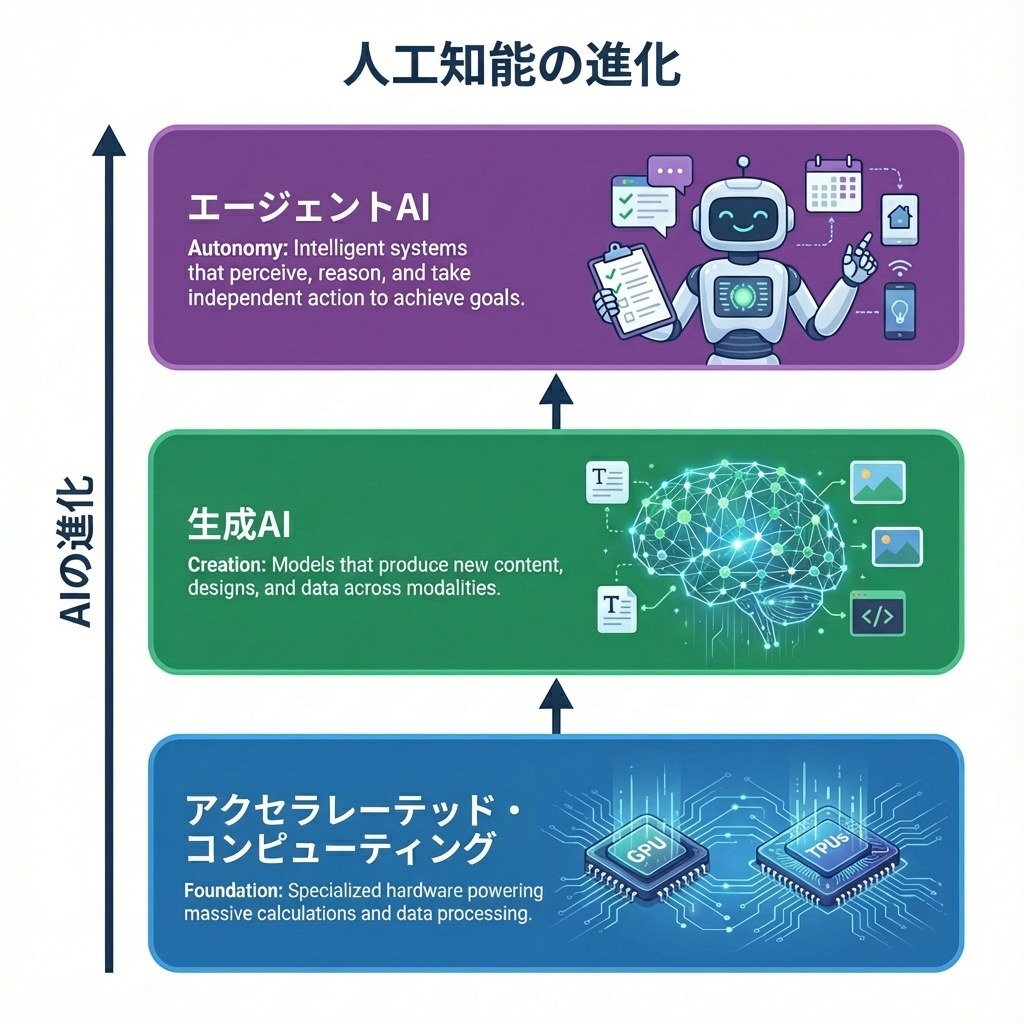

第1の移行: アクセラレーテッド・コンピューティング(基礎的かつ不可欠)
第1の移行は、CPU汎用コンピューティングからGPUアクセラレーテッド・コンピューティングへの移行です。 ムーアの法則が減速する中で、世界はデータ処理から科学技術シミュレーションまで、非AIソフトウェアに巨額の投資を行っています。これらは毎年数千億ドルのクラウドコンピューティング支出を占めています。 かつてCPU専用で動作していたこれらのアプリケーションの多くが、今や急速にCUDA GPUへと移行しています。アクセラレーテッド・コンピューティングは転換点(ティッピングポイント)に達しました。
第2の移行: 生成AI(変革的かつ不可欠)
第2に、AIも転換点に達しました。 既存のアプリケーションを変革しつつ、全く新しいものを可能にしています。 既存のアプリケーションについては、生成AIが従来の機械学習を置き換えています。検索ランキング、レコメンダーシステム、広告ターゲティング、クリックスルー予測、コンテンツモデレーションなど、ハイパースケールインフラの基盤そのものです。
MetaのGem(大規模GPUクラスターでトレーニングされた広告推奨用基盤モデル)はこのシフトを象徴しています。第2四半期にMetaは、Instagramでの広告コンバージョンが5%以上増加し、Facebookフィードでの利益が3%増加したと報告しました。これは生成AIベースのGemによるものです。生成AIへの移行は、ハイパースケーラーにとって大幅な収益増を意味します。
第3の移行: エージェントAI(革命的)
そして今、新しい波が起きています。「エージェントAIシステム」です。 これらは推論、計画、ツールの使用が可能です。CursorやClaude Codeのようなコーディングアシスタントから、AIdocのような放射線科ツール、Harveyのような法務アシスタント、Tesla FSDやWaymoのようなAIショーファー(運転手)まで。これらのシステムはコンピューティングの次なるフロンティアを示しています。
今日、世界で最も急速に成長している企業たち(OpenAI, Anthropic, xAI, Google, Cursor, Lovable, Replit, Cognition AI, Open Evidence, Abridge, Teslaなど)は、エージェントAIを開拓しています。
結論: ワン・アーキテクチャの優位性
ですから、3つの巨大なプラットフォームシフトがあるのです。 アクセラレーテッド・コンピューティングへの移行は、ムーアの法則後の時代において**「基礎的かつ不可欠」です。 生成AIへの移行は、既存のアプリやビジネスモデルをスーパーチャージするものであり、「変革的かつ不可欠」です。 そしてエージェントAIおよびフィジカルAIへの移行は、新しいアプリ、企業、製品、サービスを生み出す「革命的」**なものです。
インフラ投資を検討する際は、これら3つの基本的なダイナミクスを考慮してください。それぞれが今後数年間のインフラ成長に寄与します。 NVIDIAが選ばれる理由は、当社の単一のアーキテクチャがこれら3つの移行すべてを可能にし、あらゆる形態とモダリティのAI、あらゆる業界、AIのあらゆるフェーズ、クラウドにおける多様なコンピューティングニーズ、そしてクラウドからエンタープライズ、ロボットに至るまで対応できるからです。 **「ワン・アーキテクチャ(一つのアーキテクチャ)」**です。
Toshia、お返しします。
質疑応答セッション
Q1: 5,000億ドル売上見通しの進捗(Morgan Stanley - Joe Moore)
要約: 5,000億ドルの売上見通しは順調に進行中。KSA(サウジアラビア)40〜60万GPU、Anthropic 1ギガワットなど新規案件により、上振れの可能性あり。
Joe Moore (Morgan Stanley): ありがとうございます。2025年と2026年のBlackwellとRubinの売上について5,000億ドルというお話がありましたが、そのうち1,500億ドルはすでに出荷済みというお話もあったかと思います。四半期が終わる中で、今後14ヶ月ほどで3,500億ドルという数字はまだ一般的なパラメータとして生きているのでしょうか?また、需要の強さを考えると、その数字が上振れる可能性はあるのでしょうか?
コレット・クレス: ありがとう、Joe。はい、その通りです。私たちは5,000億ドルの予測に向けて取り組んでおり、順調に進んでいます。現在、2026暦年末までの数四半期を見通せています。数字は成長するでしょう。2026年度までに出荷可能な追加のコンピュート需要を達成できると確信しています。今四半期は500億ドルを出荷しましたが、まだ終わりではありません。おそらくさらに多くの注文を受けることになるでしょう。例えば、今日発表したKSA(サウジアラビア)との合意だけでも、3年間で40万〜60万基のGPUが追加されます。Anthropicも純増分です。ですから、発表した5,000億ドルに加えて、さらに積み増せる機会が間違いなくあります。
Q2: 供給と需要のバランス(Cantor Fitzgerald - CJ Muse)
要約: 供給逼迫は今後12〜18ヶ月以上続く見通し。3つの移行(アクセラレーテッド、生成AI、エージェントAI)により需要は継続的に拡大。既存ビジネスの置き換えはキャッシュフローで賄われ、エージェントAIは純増の新規需要。
CJ Muse (Cantor Fitzgerald): こんにちは。質問ありがとうございます。AIインフラ構築の規模と、そのような計画に資金を供給する能力やROIについて、かなりの懸念があることは明らかです。一方で、立ち上がるすべてのGPUが取り合いになっており完売状態だというお話もあります。AIの世界はまだB300、ましてやRubinや、発表されたばかりのGemini 3やGrok 5の恩恵をまだ受けていません。 この背景を踏まえて、今後12〜18ヶ月で供給が需要に追いつく現実的な道筋は見えていますか?それとも、その期間を超えて逼迫が続くとお考えでしょうか?
ジェンスン・フアン: ありがとう。まず第一に、私たちは供給計画において非常に良い仕事をしてきました。NVIDIAのサプライチェーンは基本的に世界のすべてのテクノロジー企業を含んでいます。TSMC、パッケージング、メモリベンダー、システムのODMなど、すべてのパートナーが私たちと計画を立てて素晴らしい仕事をしてくれています。私たちは大きな年に向けて計画していました。
私が先ほどお話しした3つの移行(汎用からアクセラレーテッド、生成AIによる機械学習の置換え、エージェントAI)を思い出してください。 AIは単なるエージェントAIではありません。生成AIは、ハイパースケーラーがCPUで行っていた仕事を変化させています。生成AIによって、検索やレコメンダーシステムなどが移行しています。 つまり、数千億ドルのCapEx投資は、完全にキャッシュフローで賄われているのです(既存ビジネスの置き換えだから)。 その上にあるのがエージェントAIです。これは純粋な新規の収益であり、純粋な新規消費であり、純粋な新規アプリケーションです。私が挙げた新しいアプリケーションは、歴史上最も急速に成長しています。
ですから、ハイパースケーラーを将来に向けた構築手段として見るだけでなく、世界全体、あらゆる産業を見る必要があります。エンタープライズ・コンピューティングが自らの産業に資金を供給するのです。
Q3: ギガワットあたりのNVIDIAコンテンツと資金調達(BoA - Vivek Arya)
要約: 世代が進むごとにギガワットあたりのNVIDIAシェアは増加。ワットあたり性能が収益に直結し、協調設計によりエネルギー効率が飛躍的向上。成長の大部分は既存ビジネス置き換えのキャッシュフローで賄われ、ベンダーファイナンスへの依存は限定的。
Vivek Arya (BoA): 質問をお受けいただきありがとうございます。興味があるのですが、その5,000億ドルという数字の中で、ギガワットあたりのNVIDIAのコンテンツ(売上)についてどのような前提を置いていますか?市場ではギガワットあたり250億ドルという低い数字から、300〜400億ドルという高い数字まで耳にします。 また長期的には、2030年までにデータセンター市場が3〜4兆ドルになるというお話でしたが、そのうちどれくらいがベンダーファイナンス(売り手による融資)を必要とし、どれくらいが大規模顧客や政府、企業のキャッシュフローで賄えると見ていますか?
ジェンスン・フアン: AmpereからHopper、Blackwell、Rubinへと世代が進むごとに、データセンターにおける私たちのシェア(取り分)は増加しています。 各世代でスピードアップは「Xファクター(倍数的な)」であり、顧客のTCO(総所有コスト)はXファクターで改善します。 最も重要なことは、結局のところ電力は1ギガワットしかないということです。したがって、ワットあたりの性能、アーキテクチャの効率性が極めて重要です。アーキテクチャの効率は力技では解決できません。 1ギガワットあたりの性能が、直接的にあなたの収益に変換されます。だからこそ、適切なアーキテクチャを選択することが今、非常に重要なのです。世界には無駄にできる余剰なものは何もありません。
私たちはスタック全体、フレームワーク、モデル、データセンター全体、さらには電力や冷却に至るまでサプライチェーン全体で「コ・デザイン(協調設計)」を行っています。 各世代で私たちの経済的貢献度は高くなり、提供する価値も大きくなりますが、最も重要なのはエネルギー効率が世代ごとに飛躍的に向上することです。
成長に関しては、顧客の資金調達は顧客次第です。私たちは成長の機会がかなり長い間続くと見ています。ハイパースケーラーだけに注目が集まりがちですが、誤解されているのは、NVIDIA GPUへの投資が、汎用コンピューティングからの移行におけるスケール、スピード、コストを改善するだけでなく、収益を押し上げているということです。現在のビジネスモデル(レコメンダーシステムなど)においてです。
そして、新しいエージェントAIの波が来ています。コーディングアシスタント、放射線ツール、法務アシスタント、AIショーファーなど、これらはコンピューティングの新たなフロンティアです。
Q4: 成長のボトルネックと制約要因(UBS - Tim Arcuri)
要約: 電力、資金調達、メモリ、ファウンドリなど全てが課題だが解決可能。33年のサプライチェーン管理実績で自信あり。最高のTCO・ワット性能により顧客の成功率が向上し、競合からNVIDIAへの移行が加速。
Tim Arcuri (UBS): ありがとうございます。ジェンスン、多くの顧客がメーターの裏側(自家発電等)での電力確保を進めていますが、成長を制約する可能性のある最大のボトルネックは何だと心配されていますか?電力ですか、資金調達ですか、それともメモリやファウンドリのような他の要因でしょうか?
ジェンスン・フアン: これらはすべて課題であり、制約です。私たちがしているような速度と規模で成長しているとき、簡単なことなどありません。NVIDIAがやっていることはこれまでに前例がないことであり、全く新しい産業を創出しているのです。 私たちはコンピューティングを移行させつつ、同時にAIファクトリーという全く新しい産業を作り出しています。ソフトウェアを実行するために、事前に作成された情報を検索するのではなく、トークンを生成するファクトリーが必要だという考え方です。
この移行には並外れたスケールが必要です。 サプライチェーンについては、私たちは非常にうまく管理しており、33年にわたる素晴らしいパートナーのおかげで自信を持っています。 サプライチェーンの下流(顧客側)を見ると、土地、電力、シェル(建屋)、そして資金調達において多くのプレーヤーとパートナーシップを確立しています。これらはどれも簡単ではありませんが、解決可能な問題です。
最も重要なことは、私たちが良い計画を立てることです。サプライチェーンの上流とも下流とも計画を立て、多くのパートナーと市場へのルートを確立しています。 そして非常に重要なことに、私たちのアーキテクチャは顧客に最高の価値を提供しなければなりません。最高の「TCOあたりの性能」、「ワットあたりの性能」です。私たちのアーキテクチャは、投入されたエネルギーに対して最大の収益をもたらします。私たちの成功率が高まっているのは、私たちが昨年よりも今年の方がさらに成功しているからです。
顧客が他社を検討した後に私たちのところに来る数が増えています。私がこれまでお話ししてきたこと(1つのアーキテクチャですべてをカバーできることなど)が真実であることが証明されつつあるのです。
Q5: 粗利益率とOpEx見通し(Bernstein Research - Stacy Rasgon)
要約: 2027年度も粗利益率70%台半ばを目標。入力コスト上昇に対し、コスト改善・サイクルタイム・ミックスで対応。OpExはイノベーション加速のため継続投資。サプライチェーンとの長期的な協力関係で財務計画を確実に。
Stacy Rasgon (Bernstein Research): 質問です。コレット、マージンについていくつか質問があります。 来年について、70%台半ば(mid-70s)を維持しようとしているとおっしゃいました。 まず、コスト増加の最大の要因は何ですか?メモリだけですか、それとも他にあるのでしょうか? それに対してどのような対策をしていますか?コストの最適化なのか、事前の買い付けなのか、価格転嫁なのか。 また、売上が大幅に伸びる可能性が高い中で、来年のOpEx(営業費用)の伸びをどう考えるべきでしょうか?
コレット・クレス: ありがとう、Stacy。まず今年度の状況を振り返らせてください。今年初め、コスト改善とミックスを通じて、年度末には粗利益率を70%台半ばにするとお伝えしました。私たちはそれを達成しましたし、第4四半期でも実行する準備ができています。 来年については、業界全体でよく知られている入力コスト(部材費等)の上昇があります。また、当社のシステムは非常に多くのコンポーネントで構成されており、決して単純なものではありません。これらすべてを考慮に入れていますが、コスト改善、サイクルタイム、ミックスに取り組むことで、粗利益率を70%台半ばに維持できるよう努めていくというのが、全体的な計画です。
2つ目のOpExについての質問ですが、現在の私たちの目標は、エンジニアリングチームやビジネスチームとともにイノベーションを起こし、この市場に向けてより多くのシステムを作り出すことです。ご存知のように、新しいアーキテクチャが登場します。チームはその目標を達成するために非常に忙しくしています。 そのため、ソフトウェア、システム、ハードウェアの両方でさらにイノベーションを起こすために、引き続き投資を行っていく予定です。
ジェンスン・フアン: その通りです。付け加えることは一つだけです。私たちは予測し、計画し、サプライチェーンとかなり前から交渉しています。私たちのサプライチェーンは長い間私たちの要件を知っています。 最近の急増は明らかに大きいですが、サプライチェーンは私たちと長く付き合っており、多くの場合、私たちは彼らのために多くの供給を確保しています。なぜなら、彼らは世界最大の企業と仕事をしているからです。 財務面でも緊密に連携し、予測や計画を確実なものにしています。これらすべてが私たちにとってうまくいっています。
閉会
Toshia Hari: ありがとうございました。最後に閉会の挨拶をさせていただきます。 12月2日に開催されるUBSグローバル・テクノロジー&AIカンファレンスに参加する予定です。 また、2026年度第4四半期の決算発表は2月25日を予定しています。 本日はご参加いただきありがとうございました。オペレーター、通話を終了してください。
オペレーター: 本日の電話会議は以上で終了です。切断していただいて構いません。
まとめ
NVIDIA 2026年度第3四半期決算説明会では、売上高570億ドル(前年比62%増)という驚異的な成長を達成し、AI市場における圧倒的なリーダーシップを示しました。
主要ポイント:
- Blackwell・Rubinで2026年末までに5,000億ドルの売上見通し
- データセンター売上510億ドル、ネットワーキング82億ドル(前年比162%増)
- 3つのプラットフォームシフト(アクセラレーテッド・コンピューティング、生成AI、エージェントAI)が同時進行
- OpenAI 10ギガワット、Anthropic 1ギガワットの戦略的パートナーシップ
- 粗利益率73.6%を維持し、Q4見通し650億ドル
NVIDIAは単なるGPUメーカーから、AI時代のインフラ全体を提供するプラットフォーム企業へと進化を遂げています。